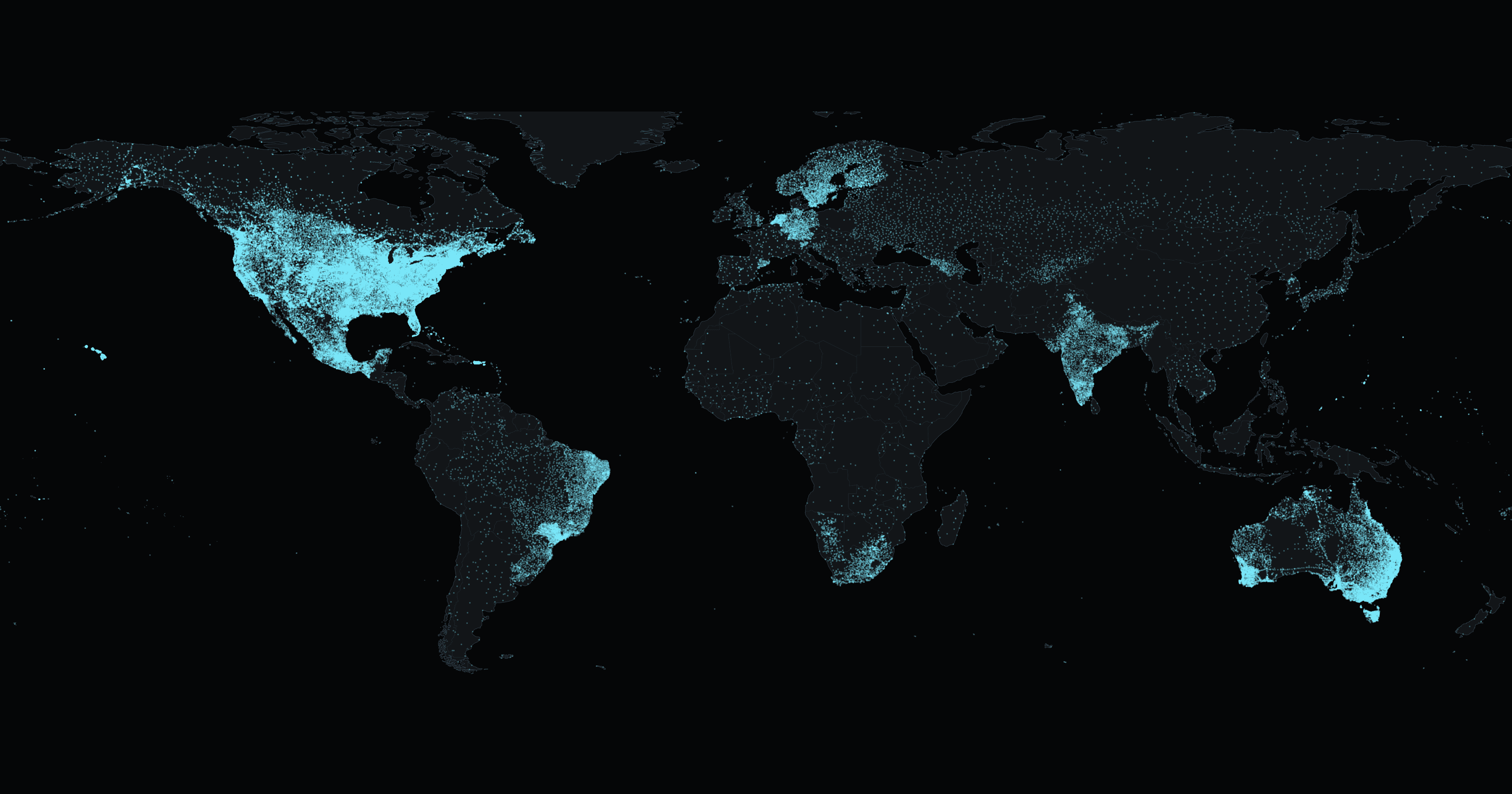
Chat with the World's Entire History of Weather Data
All you need is a Databricks account, 10 minutes, and $7, and you will be able to ask 3 billion weather records anything in plain English. That's the entire known history of daily measurements from weather stations globally. The possibilities are endless: explore climate change trends, plan your vacations, or settle arguments at the dinner table.
Tutorial
Below are step-by-step instructions to load the data, configure the Genie Space, and start asking questions. The source code is in my public GitHub repo.
Deploy and run the assets in Databricks
Configure the Databricks CLI and authenticate to an existing workspace. Clone the repo, set your target catalog , and run:
export BUNDLE_VAR_catalog=main # or any UC catalog you can write to
databricks bundle deploy
databricks bundle run ingest
databricks bundle run setup
Boom. 10 minutes later you have the entire history of global weather loaded as managed tables in Unity Catalog, a chat interface that handles hard analytical questions, and a foundation to keep building on. Not bad.
Let's look at the tech that made this so fast.
Lakeflow Spark Declarative Pipeline
The pipeline reads data from a public S3 bucket and writes to Delta tables. Incremental ingestion comes out of the box - Autoloader tracks file changes in the bucket and merges new data into the target tables automatically. Schedule it however you like (hourly, daily, weekly); each run only picks up files that arrived since the last checkpoint.
The code is delightfully simple:
def weather():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("header", "true")
.load("s3a://noaa-ghcn-pds/csv/by_year/")
It runs on serverless compute, so there's no cluster config — the platform spins up what's needed and scales back to zero when the run completes.
End-to-end: under 10 minutes to load 3 billion records. Nice!
Delta Lake + Unity Catalog
The entire world’s history of weather now sits in a single table, optimized for read performance, and annotated with comments pulled straight from NOAA GHCNd.
Now we're ready to "talk with the data".
SQL Warehouse + Genie Space
The Genie Space runs on a SQL warehouse for fast queries and built-in access control. Tables come with metadata like column comments and PK/FK relationships. Custom instructions help steer the responses.
Asking Questions
Now the fun begins. Let's start by asking about climate change.
Ok, lighter subject: vacations.
The richness of these responses is kind of mindblowing. Hawaii, Spain, Philippines, Australia... brb booking flights.
Next Steps
This is where it gets interesting. A few directions worth exploring:
Ask more questions. Dig into other weather factors such as precipitation, the impact of elevation, or explore data quality issues.
Launch a Databricks App to explore the data on an interactive map.
Ingest more data. Pull in additional sources, historical or simulated. Mix in unstructured data like personal stories from extreme weather events. Build a knowledge engine on the past and future of our Earth's climate.